Daten aus Bewerbungsprozessen beurteilen
Lektion 3
In Daten lesen
Yunus: Na, wie lief dein Bewerbungsgespräch?
Mara: Ganz gut. Ich glaube, ich habe gute Chancen. Aber die meiste Zeit haben wir eigentlich über diese neuen digitalen Bewerbungs-Tools gesprochen.
Yunus: Worüber?
Mara: Na, diese Algorithmen, über die sie überhaupt auf mich gekommen sind.
Yunus: Ach so, ja. Und? Hast du etwas Neues gelernt?

Mara: Ja, ich wusste nicht, was schon alles möglich ist, und wie viel man aus den Daten lesen kann, die jemand hinterlässt. Es gibt wohl schon Analyse-Programme, die aus deiner Stimme auf deinen Charakter schließen können.
Yunus: Also, ob das so seriös ist? Aber es stimmt schon: Man kann inzwischen wirklich viel über einen Menschen herausfinden, nur durch Kombination von Daten.
Mara: Was meinst du jetzt?
Yunus: Na, die Produkte, die du online kaufst, oder die Dinge, die du auf Social-Media-Portalen postest. Daraus lässt sich eine Menge ableiten. Die Frage ist, zu welchem Zweck? Und bleibt das Ganze noch nachvollziehbar?
Wie kreditwürdig bist du?
Aus personenbezogenen Daten Verhaltensprognosen abzuleiten nennt man Scoring. Dieses Verfahren ist nicht nur für Bewerbungsprozesse relevant.
Bekannt ist etwa das Kreditscoring. Dabei berechnen private Unternehmen für eine Person einen Wert – den Score. Er soll die Kreditwürdigkeit widerspiegeln.
Banken möchten damit schneller bewerten, welchen Personen sie einen Kredit gewähren wollen. Vermieter*innen nutzen solche Scores, um sicherzustellen, dass Mieter*innen zahlungskräftig sind.
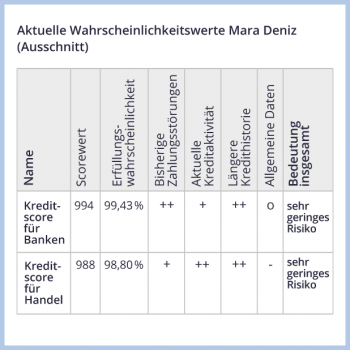
Grundlage für das Kreditscoring sind mehrere Finanzdaten einer Person, beispielsweise, ob sie Rechnungen stets rechtzeitig beglichen hat oder aber Kredite nicht zurückzahlen konnte. Dazu kommen allgemeine Informationen, etwa ein erlassener Haftbefehl.
Dieser individuelle Datensatz wird mit denen anderer Menschen verglichen und das Ergebnis tabellarisch dargestellt. Ein „++“ zeigt ein unterdurchschnittliches Risiko an, ein „–“ ein leicht erhöhtes. Mit den einzelnen Werten wird eine Risikobewertung vorgenommen und ein Score berechnet.
Ein hoher Scorewert zeigt eine hohe Kreditwürdigkeit und damit dem Kreditgeber ein geringes Risiko an. Welche Daten verwendet werden und welches Gewicht sie bei der Berechnung haben, ist oft nicht ersichtlich.
Exercise:
Teste dein Wissen!
Diskriminierung durch Algorithmen
Maschinelle Datenanalyse kann dazu beitragen, Entscheidungen evidenzbasiert und somit nicht nach Bauchgefühl oder persönlichen Vorlieben zu treffen. Evidenzbasierte Entscheidungen sind aber nicht zwangsläufig besser: Trotz der Nutzung von Algorithmen kann es zu unethischen oder fragwürdigen Entscheidungen kommen.
Basis aller Entscheidungen sind die Daten, die genutzt werden und die von Menschen produziert werden, ebenso wie die Anwendungen, die die Daten verarbeiten. Daher können maschinell ausgewertete Daten individuelle Präferenzen, Stereotype oder andere Verzerrungen widerspiegeln und es kann zu Diskriminierungen kommen.

In einem Kreditscore kann der Wohnort einer Person als Anhaltspunkt verwendet werden, um auf die Einkommensverhältnisse zu schließen. Wer in einem sogenannten Problembezirk gemeldet ist, so die Annahme, verfügt mit einer hohen Wahrscheinlichkeit über ein geringeres Einkommen und erhält deshalb einen geringeren Scorewert.
Ist in einer solchen Wohngegend dann noch eine Minderheit überrepräsentiert, könnte es dazu führen, dass Angehörige dieser Minderheit überdurchschnittlich oft mit dem Attribut „wenig kreditwürdig“ versehen werden. Sie bekommen pauschal einen schlechteren Kreditscore und werden diskriminiert.
Selbst wenn man sich bemühen würde, solche Fehlschlüsse auszuschließen und diskriminierende Variablen zu vermeiden: Ein Score kann auf viele Hundert Merkmale zurückgreifen. In ihnen können dennoch Daten enthalten sein, die mit diskriminierenden Mustern zusammenhängen, etwa die Unterscheidung bei Berufsbezeichnungen in männliche und weibliche Formen (Ingenieur und Ingenieurin). Deshalb ist es wichtig, die Datengrundlage und maschinelle Entscheidungssysteme genau zu prüfen.
Exercise:
Was meinst du, welche Datengrundlage könnte zu welchen Verzerrungen oder Diskriminierungen führen?
Mensch und Maschine
Obwohl Anwendungen mit dem Risiko behaftet sind, voreingenommen zu entscheiden, können Mensch und Maschine ein gutes Team bilden. Voraussetzung ist, dass Entscheidungen der Anwendung transparent und nachvollziehbar sind. So bestehen gute Chancen, Diskriminierung zu verhindern. Dafür eignen sich manche Verfahren eher als andere.
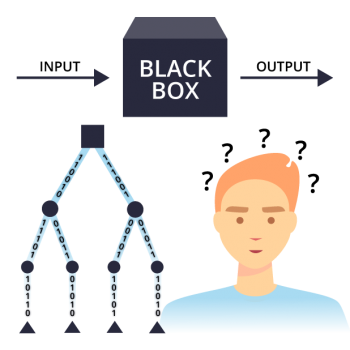
Sogenannte „Deep Learning“-Algorithmen funktionieren nach dem „Black-Box“-Prinzip: Von außen ist nicht mehr erkennbar, wie sie Entscheidungen treffen.
Transparenter arbeiten Entscheidungsbäume, die nach klaren Regeln entscheiden: „Wenn Merkmal A vorliegt, dann mache B.“
Entscheidungsprozesse bei Menschen sind übrigens nicht so transparent, wie man oft annimmt. Die Motive unserer Handlungen bleiben für unsere Mitmenschen oft im Dunkeln oder sind schwer zu interpretieren.
Bei Computerprogrammen dagegen lassen sich Input und vor allem Output genau überwachen. Manche Expert*innen sehen es deshalb als gar nicht abwegig an, dass maschinelle Entscheidungsprozesse in Zukunft sogar transparenter gestaltet werden könnten als menschliche.

Exercise:
Deine Meinung ist gefragt!